Lua Coroutines, which we discussed before in other tutorials, offer a nice way of running long calculations step by step every frame over a period of time, so your programs do not appear to be stuck or frozen while you wait for those functions to return. Unfortunately, Coroutines do not offer true multithreading, which means that your expensive multicore CPU largely goes underutilized. Thanks to ShiVa’s underlying C++ core, Lua Coroutines are not the only way to design parallel operations. Using the power of the C++11 STL, you can achieve true concurrency via std::thread(). Part 1 this week will go into the basics and show you how to create threads without data races.
Setup
This tutorial requires a C++11 compliant compiler. For the majority of readers, this will be
Visual Studio 2015 or above. Since we are exclusively using the STL to manage our threads,
there will be no need for you to manually take care of hardware-dependent code. The same
source should therefor compile in GCC 4.7+ and Clang 3.1+ (Xcode 4.5+) without any
changes.
When you compile with Clang or GCC, make sure you add the directive
-std=c++11
to the make file compiler flags, or change the C++ language dialect in Xcode
respectively.

Lua timer
For this tutorial, I am also using a timer function that ticks forward every second and outputs its state to the log, so it is easy to detect when an application is stalling or something interferes with the log.
local cft = this.curFrametime ( )
local dt = application.getLastFrameTime ( )
local sum = (cft + dt)
if sum > 1 then
local s = this.secs ( ) + 1
log.message ( "Time: " ..s )
this.secs ( s )
this.curFrametime ( sum - 1 )
else
this.curFrametime ( sum )
end
Plugin
For ease of use, the thread code will be inside a C++ plugin, so that we do not have to export a native project every time we make small changes to the application inside ShiVa. You need to create a new plugin in either ShiVa 1.9.2 or 2.0 – either will work – and give it some basic functions:
bOK = thr.init(sAI) --init plugin with target AI name
bOK = thr.launchTimerThreads(nThreads) --create a number of threads
The .init function will merely check the AI string and store it, so we can use it later in the tutorial when we need to send data back.
const char* _sAI = "test_threading";
int Callback_thr_init ( int _iInCount, const S3DX::AIVariable *_pIn, S3DX::AIVariable *_pOut )
{
// [...]
// Output Parameters
S3DX::AIVariable bOK ;
{
auto in = sAI.GetStringValue();
if (in == nullptr || in[0] == '\0') bOK.SetBooleanValue(false);
else _sAI = in;
bOK.SetBooleanValue(true);
}
// [...]
}
You also need to include some additional STL headers on top of your MultiThreadingPlugin.cpp file:
#include <thread>
#include <atomic>
#include <chrono>
#include <mutex>
Anatomy of a Thread
There are a number of ways to create threads, the two most common ones are calls to
std::thread() and std::async(). Since async() lives in the
std::thread t(someThread); // valid, no arguments
std::thread t(someThread, 12); // passing 12 to someThread()
Generally speaking, a thread will call upon a function to execute and optionally pass
arguments to that function. The thread will then run until completion and finish, which will
take down your entire process (= game). To prevent that, threads either need to be joined or
detached. The .join() function will wait for a thread to finish and then return the result,
while detach() will immediately allow the caller to continue working, turning the detached
thread into a background daemon. For our use in ShiVa, detached processes will be our main
focus. Joined processes can still be used to further parallelize long calculations, however
the go-to in ShiVa will be detach().
For instance, your program needs to calculate all primes from 2 to 4 million. You would
first detach() a thread that manages the prime calculation. Inside the detached thread, you
would then spawn 4 threads which each calculated a portion of the problem, like 2..1M,
1M..2M, 2M..3M and 3M..4M, after which you will join these sub-threads since you can now
afford to wait. The main ShiVa game thread will not be blocked since the parent thread of
these joined threads is still detached.
You can call join() and detach() only once for any given thread. To prevent errors, always
check threads you wish to join() by testing against .joinable(). Threads that have been
detached once cannot be joined afterwards.
For an in-depth introduction to C++11 threads, please read bogotobogo.com/cplusplus/multithreaded
Your first Thread
For our first test, we will create 4 independently running threads which take 3 seconds each to complete, and then output a short message to the log as soon as a thread finishes. The Lua call is of course trivial:
thr.launchTimerThreads ( 4 )
The corresponding C++ function makes use of STL threads for the first time:
int Callback_thr_launchTimerThreads ( int _iInCount, const S3DX::AIVariable *_pIn, S3DX::AIVariable *_pOut )
{
S3DX_API_PROFILING_START( "thr.launchTimerThreads" ) ;
// [...]
// Output Parameters
S3DX::AIVariable bOK ;
for (int i = 0; i < nThreads.GetNumberValue(); ++i) {
std::thread t(timerThread, i);
t.detach();
}
bOK.SetBooleanValue(true);
// [...]
}
As you can see, the function spawns threads in a for-loop until nThreads is reached. These
threads call on a function named "timerThread" and pass a single argument "i" along, which
will be used for keeping track. After thread creation, the threads are then immediately
detached. This effectively puts them into the background, so the function can return without
waiting for the threads to finish.
The thread function itself is equally simple. At first, the threadID gets converted into a
const char* so ShiVa can log it, then a bunch of status logging follows. The function sleeps
for a bit afterwards while keeping track of time, and logs again when it wakes up.
void timerThread(int threadID) {
std::stringstream sstr;
sstr << std::this_thread::get_id();
const auto& tids = sstr.str();
auto tid = tids.c_str();
S3DX::log.message("T", threadID, " (", tid, ") started");
S3DX::log.message("T", threadID, " (", tid, ") will start a clock");
S3DX::log.message("T", threadID, " (", tid, ") waits for 3s now");
using namespace std::chrono_literals;
auto start = std::chrono::high_resolution_clock::now();
std::this_thread::sleep_for(3s);
auto end = std::chrono::high_resolution_clock::now();
std::chrono::duration elapsed = end - start;
S3DX::log.message("T", threadID, " (", tid, ") ended");
S3DX::log.message("T", threadID, " (", tid, ") ran for ", (float)elapsed.count(), "ms");
S3DX::log.message("T", threadID, " (", tid, ") will now return");
return;
}
Welcome to the races
The threads are launched one after the other with a for-loop, so they should start and end in sequence: Launch one after the other, run in parallel, then finish one after the other. We naively assume the following output:
T0 (#tid) started T0 (#tid) will start a clock T0 (#tid) waits for 3s now -- same for T1, T2, T3 -- now some waiting messages from the ShiVa timer -- then the end messages: T0 (#tid) ended T0 (#tid) ran for 3000 ms T0 (#tid) will now return -- same for T1, T2, T3
But this is not what we get. Not only do the threads not start in sequence T0-3, but the
messages order also changes all the time (T1 T0 T2 T4 - T3 T2 T4 T0 - etc.). On top of that,
there are true mistakes in the output, like a double log of T0 (in red). Times are never
exactly 3 seconds either. In short, the log looks nothing like we expected.
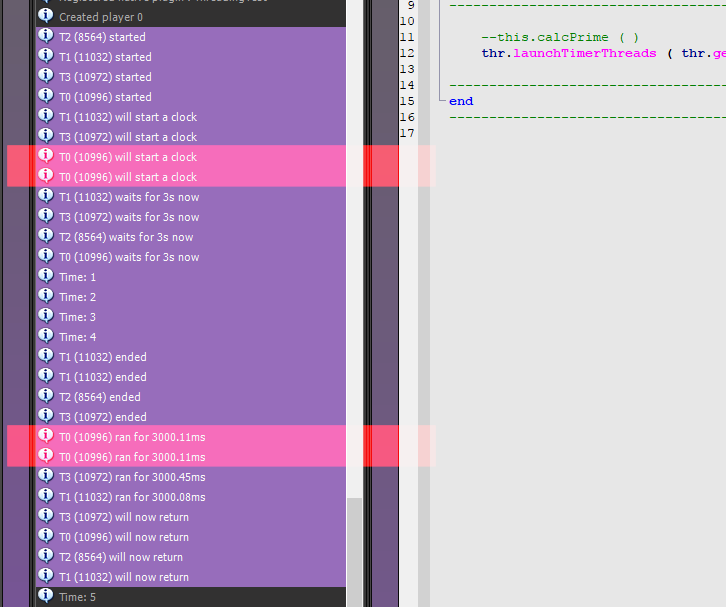
What we have inadvertently created is known as a data race. A data race occurs when:
1. two or more threads (= our timerThread) in a single process (= ShiVa application) access
the same memory location concurrently, and
2. at least one of the accesses is for writing, and
3. the threads are not using any exclusive locks to control their accesses to that
memory.
The shared resource our threads are trying to write to (1.) is the string buffer for
S3DX::log.message. Since we only have this interface for logging, we cannot change our code
here.Neither can we do changes in (2.) since logging requires writing to that buffer, and
all threads just happen to finish at roughly the same time. Our only chance to solve this
problem is (3.): We need to manage write access to the log by introducing some sort of
locking mechanism.
A simple locking mechanism
The two most important multithreaded locking/organizational mechanisms are mutexes and
atomics. Mutexes are generally easier to implement, but have the unfortunate side effect of
stalling other threads that use the same lock, while atomics allow for lock-free
concurrency, but are somewhat harder to understand and correctly to program. We will focus
on mutexes for now.
A calling thread owns a mutex from the time that it successfully calls either lock or
try_lock until it calls unlock. When a thread owns a mutex, all other threads will block
(for calls to lock) if they attempt to claim ownership of the mutex. In our case, calling
"lock" on a mutex that is shared across our timerThreads at the right time will ensure that
only one of these threads will be active at that time. It is therefor imperative that you
keep your mutex-protected code sections as short as possible and unlock the mutex as soon as
you are done.
Let's fix our tutorial code by introducing a mutex:
std::mutex mu_timer;
void timerThread(int threadID) {
// [...]
{
std::lock_guard mylock(mu_timer);
S3DX::log.message("T", threadID, " (", tid, ") started");
S3DX::log.message("T", threadID, " (", tid, ") will start a clock");
S3DX::log.message("T", threadID, " (", tid, ") waits for 3s now");
}
// [...]
}
First, we declare the mutex "mu_timer" outside the thread context. We then wrap it inside a
"std::lock_guard" which provides a convenient RAII-style mechanism for owning a mutex for
the duration of a scoped block. When a lock_guard object is created, it attempts to take
ownership of the mutex it is given. When control leaves the scope in which the lock_guard
object was created, the lock_guard is destructed and the mutex is released. The protected
section of the code must therefor be wrapped inside its own scope {}.
I only wrapped the thread starter messages and secured them with a lock guard, so we can see
the difference between the "mutexed" starter and "unmutexed" end messages: Even though the
thread launch is now in order, we still cannot make any assumptions about the end messages
of the threads, which change every time the program starts.
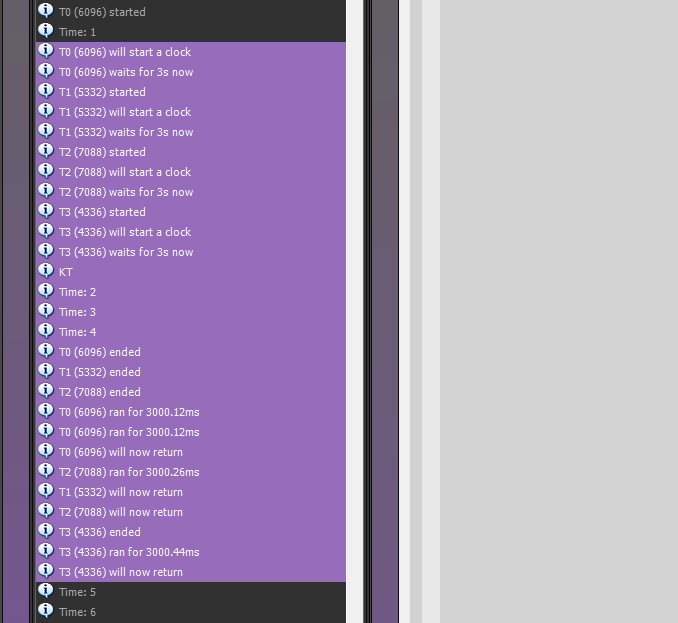
Summary
C++11 turned C++ into a multithreaded language that supports multithreading on a language
level without the need for platform- or OS-specific threading code on the user level. The
most use ShiVa developers will get out of std::thread is through detach(), which gives you
the freedom to offload long calculations onto otherwise underutilized CPU cores and compute
the result without stalling the main game thread. As soon as you have multiple threads
reading and writing from and to the same resource(s), you open yourself up for horrible data
races which must be avoided at all cost. The easiest way to avoid races is through
lock_guarded mutexes.
Next week, we are going to have a look at how to retrieve the results from threaded
calculations, we will explore how user AIs can offload long calculations into ShiVa AIModel
states, and write a custom spinlock with atomics.