Now that we are familiar with spawning and detaching threads, know about data races and lock_guarded mutexes, it’s time to put all that knowledge to good use and make all those threads do actual work in your ShiVa game! In this tutorial, we will be looking at two possible design patterns for currentUser() AIModels, while next week will have a look at multithreading in scene object AIs.
Events and State loops
In general, there are two built-in ways in ShiVa to capture the result of a part of the
program that may take a long time, or may give you a result at an unknown time.
For one, there are APIs that require or work best in state loops. ShiVa’s XML API is
one of those, cache.* another. Since you cannot know how long these processes will take,
because filesize, internet connection speed, computer performance etc. are all unknown
variables, we always recommend writing these operations using a separate state with a
polling loop that checks on the status of the process:
--------------------------------------------------------------------------------
function Main.loadResources_onEnter ( )
--------------------------------------------------------------------------------
cache.addFile ( "ResourcePack.stk", "http://yourserver/ResourcePack.stk" )
log.message ( "loading resource: ResourcePack.stk" )
--------------------------------------------------------------------------------
end
--------------------------------------------------------------------------------
--------------------------------------------------------------------------------
function Main.loadResources_onLoop ( )
--------------------------------------------------------------------------------
local nProgress = cache.getFileStatus ( "ResourcePack.stk" )
if (nProgress == 1) then
-- go to another state and leave the loop
this.idle ( )
end
--------------------------------------------------------------------------------
end
--------------------------------------------------------------------------------
The AIModel “Main” above has two states, “idle” and “loadResources.”
When we switch to the “loadResources” state, we first instruct ShiVa to start
loading the remote STK from a server in the state onEnter() function, but we will not
immediately succeed with that request. Instead, the onLoop() function queries the progress
every frame. When getCachedFileStatus() has reached 1, onLoop() will switch over to the
idle() state and exit itself.
The other method of waiting for events are ShiVa’s event handlers:
--------------------------------------------------------------------------------
function test_threading.onKeyboardKeyDown ( kKeyCode )
--------------------------------------------------------------------------------
if kKeyCode == input.kKeyH then
log.message ( "H key pressed!" )
end
--------------------------------------------------------------------------------
end
--------------------------------------------------------------------------------
They provide a very clean and efficient interface without writing busy loops as we did above,
since all required polling is done on an engine level. You neither had to initialize the
keyboard, nor write a busy waiting loop that polls all keys every frame in order to capture
the event above. Imagine you actually had to write a polling function yourself for every
keystroke, every mouse movement, or every user joining your multiplayer session, how
inefficient that would be – fortunately you don’t have to with ShiVa’s
event system. However if you are an older developer, you may very well remember the days
where lots of busy waiting mostly through while() loops was quite common in the game engines
of 10, 20 years ago.
Both design patterns, states and event handlers, have their use in SMP/parallel systems.
Since active polling akin to the caching API is easier to code, we will implement it first.
State for single detached thread
Using a state over an event is usually done for 2 reasons: One, you require progress
monitoring, and two, because you are only firing the thread off once. To go back to the
caching example, you only need to getrieve the file once, and you would like to get feedback
on how far the process has come. You could ask for different files to be cached, but caching
the same file multiple times at the same time makes little sense. This is important to keep
in mind, since we always have to keep an eye out for potential data races. If you could
launch a cache-like thread multiple times and write to the same location in memory while
simultaneously reading its progress, that sounds like a classic scenario for a race
condition. With a single cache-like thread and a state configuration that looks like the
example above, we know that we will only have one reader and one writer function to
synchronize.
For this tutorial, I wrote a horribly inefficient prime number calculator which calculates
all primes up to a certain limit. When limited to 150000, the function is slow enough to
stall my i5-6500 test system for 3 seconds at 100% single CPU core usage. The goal will be
to offload this calculation onto a separate thread, so it can run in parallel to the ShiVa
thread without freezing the game. As we know form the caching example, we will need:
– a new state “calcPrime” which manages the prime number calculation,
– a function like “addFile” in onEnter() which launches the thread,
– a function like “getFileStatus” to monitor the progress in onLoop(),
– and some sort of accessor function which returns the prime number that was
computed
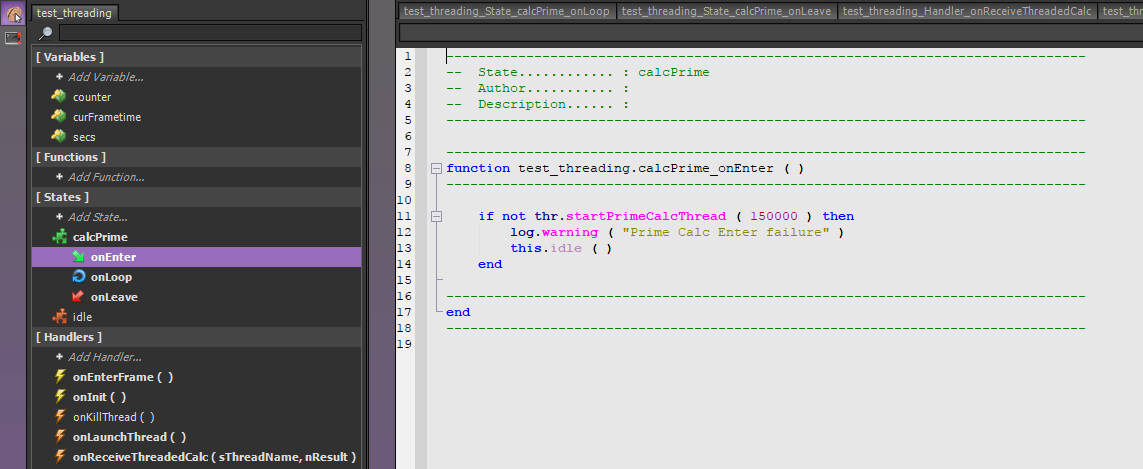
This is not difficult:
--------------------------------------------------------------------------------
function test_threading.calcPrime_onEnter ( )
--------------------------------------------------------------------------------
if not thr.startPrimeCalcThread ( 150000 ) then
log.warning ( "Prime Calc Enter failure" )
this.idle ( )
end
--------------------------------------------------------------------------------
end
--------------------------------------------------------------------------------
--------------------------------------------------------------------------------
function test_threading.calcPrime_onLoop ( )
--------------------------------------------------------------------------------
if thr.isCalcDone ( ) then this.idle ( ) end
--------------------------------------------------------------------------------
end
--------------------------------------------------------------------------------
--------------------------------------------------------------------------------
function test_threading.calcPrime_onLeave ( )
--------------------------------------------------------------------------------
local r = thr.getLastPrime ( )
if r ~= nil then
log.message ( "Last prime: " ..r )
else
log.warning ( "PRIME FAILED" )
end
--------------------------------------------------------------------------------
end
--------------------------------------------------------------------------------
The method of spawning the thread is not really different from last week, minus the for-loop:
int Callback_thr_startPrimeCalcThread ( int _iInCount, const S3DX::AIVariable *_pIn, S3DX::AIVariable *_pOut )
{
// Input Parameters
// etc. [...]
// Output Parameters
S3DX::AIVariable bStartedSuccessfully ;
{
std::thread primeT(calcPrimes, (int)nLimit.GetNumberValue() );
primeT.detach();
bStartedSuccessfully.SetBooleanValue(true);
}
// Return output Parameters
// etc. [...]
}
calcPrimes is our threaded function, which is written as follows:
// 0:ready, 1:working, 2:done
std::atomic lock_primes = 0;
S3DX::AIVariable biggestPrime;
void calcPrimes(const int && limit) {
// atomic check
if (lock_primes.load(std::memory_order_acquire) == 1) {
S3DX::log.warning("THREAD already running");
return;
}
// atomic set
lock_primes = 1;
S3DX::log.warning("THREAD start");
int lastPrime = 0;
// really awful prime function you should never write goes here
// it stores the last prime before the limit into lastPrime
// [...]
// return to global
biggestPrime.SetNumberValue(lastPrime);
// atomic release
lock_primes = 2;
return;
}
At first glance, you will note that we are not locking anything with lock_guard and mutexes,
although our target output “S3DX::AIVariable biggestPrime” can be accessed from
readers (progress checking) and writers (thread function) at potentially the same time,
leading to undefined behaviour. Instead, we are are declaring a separate control variable
lock_primes of type atomic
Our guaranteed data-race free atomic
For the C++ code for the onLoop() check is extremely simple. Since we are using the
atomic variable again, we can be sure that this reader function is race free with
the calcPrimes() writer thread:
int Callback_thr_isCalcDone ( int _iInCount, const S3DX::AIVariable *_pIn, S3DX::AIVariable *_pOut )
{
// [...]
S3DX::AIVariable bDone ;
bDone.SetBooleanValue(false);
if (lock_primes.load(std::memory_order_acquire) == 2)
bDone.SetBooleanValue(true);
// Return output Parameters
// [...]
}
As for the return in onLeave, we can use Lua’s dynamic typing system to return either a number value on success or NIL on failure:
int Callback_thr_getLastPrime ( int _iInCount, const S3DX::AIVariable *_pIn, S3DX::AIVariable *_pOut )
{
// [...]
// Output Parameters
S3DX::AIVariable nPrime ;
if (lock_primes.load(std::memory_order_acquire) == 2)
nPrime = biggestPrime;
else
nPrime.SetNil();
// Return output Parameters
// [...]
}
This code will work, but it is neither elegant nor scaleable. Furthermore, the interface is easy to use incorrectly. You should always aim to write interfaces that are easy to use correctly and hard to use incorrectly. If you call these functions from ShiVa in any other way than we did with the state, it will not work. If want to do multiple prime calculations at once, it will not work. If you want to execute another thread, you will have to write another busy waiting loop. As I said before, if you just need to launch a single thread in a cache.*-like scenario, this will be fine, but we can definitely do better.
The event handler approach
Using ShiVa’s event system is a much better solution for threaded operations that need to be fired off repeatedly. Using event handlers also results in a safer design pattern that is much easier to use and harder to abuse. For starters, you do not need a separate state to create your thread, neither do you need to write a custom busy loop in Lua. You do however need a way to identify your threads, so you can associate the result you get in the event handlers with the function call that launched the thread. This can be done either with an identifier string, like cache.getFileStatus ( “ResourcePack.stk” ) where you identify the resource/thread by name, or with an automatically generated handle, like hObject = scene.createRuntimeObject ( hScene, sModel ), although hObject is not a thread handle of course. I opted for an identifier string, only because it is less code:
--------------------------------------------------------------------------------
function test_threading.onLaunchThread ( )
--------------------------------------------------------------------------------
-- without separate state, using event handler
if not thr.launchNamedPrimeThread ( "ShiVaThread1", 130000 ) then log.warning ( "T1 launch failure" ) end
if not thr.launchNamedPrimeThread ( "ShiVaThread2", 140000 ) then log.warning ( "T2 launch failure" ) end
if not thr.launchNamedPrimeThread ( "ShiVaThread3", 150000 ) then log.warning ( "T3 launch failure" ) end
--------------------------------------------------------------------------------
end
--------------------------------------------------------------------------------
Here I am attempting to launch 3 prime number threads from a custom AIModel handler. The function takes 2 parameters, first the identifier, and then the limit as before. Launching these threads is essentially the same as before, though we call a new thread function “calcNamedPrimes” now that takes 2 parameters:
int Callback_thr_launchNamedPrimeThread ( int _iInCount, const S3DX::AIVariable *_pIn, S3DX::AIVariable *_pOut )
{
// [...]
// Input Parameters
int iInputCount = 0 ;
S3DX::AIVariable sName = ( iInputCount < _iInCount ) ? _pIn[iInputCount++] : S3DX::AIVariable ( ) ;
S3DX::AIVariable nLimit = ( iInputCount < _iInCount ) ? _pIn[iInputCount++] : S3DX::AIVariable ( ) ;
// Output Parameters
S3DX::AIVariable bOK ;
{
std::thread primeT(calcNamedPrimes, std::string(sName.GetStringValue()), (int)nLimit.GetNumberValue());
primeT.detach();
bOK.SetBooleanValue(true);
}
// Return output Parameters
// [...]
}
Let's have a look at this new "calcNamedPrimes" thread function and all its required supplementary code next.
typedef struct {
std::string name;
int result;
} primeData;
std::vector vPrimeData;
std::mutex mu_vPrimeData;
// [...]
void calcNamedPrimes(std::string && name, int && limit) {
S3DX::log.warning("namedTHREAD start");
// initialize struct
primeData P { std::move(name), 0 };
int lastPrime;
// really awful prime function you should never write goes here
// it stores the last prime before the limit into lastPrime
// [...]
// modify struct
P.result = lastPrime;
// publish result, don't forget to lock
{
std::lock_guard<:mutex> _(mu_vPrimeData);
vPrimeData.push_back(std::move(P));
}
return;
}
I defined a custom type "primeData" to hold both the identifier and the result. The idea is to compose primeData objects in the thread and push them back into the vector "vPrimeData" as soon as the calculation is done. Since multiple threads could write to the vector container at the same time, we also need a mutex "mu_vPrimeData" to protect against races. For performance reasons, it is important that the vector has a proper capacity, so it can take all results without the need of being resized/reallocated. You definitely should reserve some capacity in the plugin init() we wrote last week:
int Callback_thr_init ( int _iInCount, const S3DX::AIVariable *_pIn, S3DX::AIVariable *_pOut )
{
// [...]
{
auto in = sAI.GetStringValue();
if (in == nullptr || in[0] == '\0') bOK.SetBooleanValue(false);
else _sAI = in;
vPrimeData.reserve(std::thread::hardware_concurrency() );
bOK.SetBooleanValue(true);
}
// [...]
}
We assume the Lua programmer is smart enough not to launch more threads than the hardware can
support at the same time. The capacity of the vector is therefor determined by the number of
hardware threads on the processor: "std::thread::hardware_concurrency()". Naturally, you can
set the capacity of the vector to any value you like, while bigger is always safer.
The last piece to the puzzle is a polling function that takes a look at the result vector
and pushes its contents into ShiVa event handlers. Since the function also clears the vector
after all events have been sent, we must not forget to lock_guard this section of code.
int Callback_thr_threadEventHandlerLoop ( int _iInCount, const S3DX::AIVariable *_pIn, S3DX::AIVariable *_pOut )
{
// [...]
{
std::lock_guard<:mutex> _(mu_vPrimeData);
if (!vPrimeData.empty()) {
for (auto & d : vPrimeData)
S3DX::user.sendEvent(S3DX::application.getCurrentUser(), _sAI,
"onReceiveThreadedCalc", d.name.c_str(), (float)d.result);
vPrimeData.clear();
}
}
// [...]
}
Since we need to call this function every frame, just put it inside the onEnterFrame() handler of your thread AI:
--------------------------------------------------------------------------------
function test_threading.onEnterFrame ( )
--------------------------------------------------------------------------------
thr.threadEventHandlerLoop ( )
-- last week's timer code goes here
--------------------------------------------------------------------------------
end
--------------------------------------------------------------------------------
Unlike the onLoop() polling code in the state example above, this approach is scaleable and
efficient. If you ever need to extend your AI with another thread, you can use the same
function for another vector/queue to dispatch events.
Speaking of events, receiving them in your AI is now trivial:
--------------------------------------------------------------------------------
function test_threading.onReceiveThreadedCalc ( sThreadName, nResult )
--------------------------------------------------------------------------------
log.message ( "'", sThreadName, "' THREADED CALC RESULT: ", nResult )
--------------------------------------------------------------------------------
end
--------------------------------------------------------------------------------
One possible output on my test machine looks like this:

Summary
For singular operations that take a long time, using states is most convenient. If you need more flexibility and plan on spawning multiple threads using the same calculation, a result queue combined with ShiVa's event system and a singular polling loop is the far better option. Both methods require some sort of busy looping/spinning, and both require locking/synchronization, either through atomics or mutexes. Next week, we will be diving into object AI code, static object handles and see what the ShiVa API can do for us in threads.